
Research Interests
AI Chip Research Philosophy (Cross-Stack Co-Design)
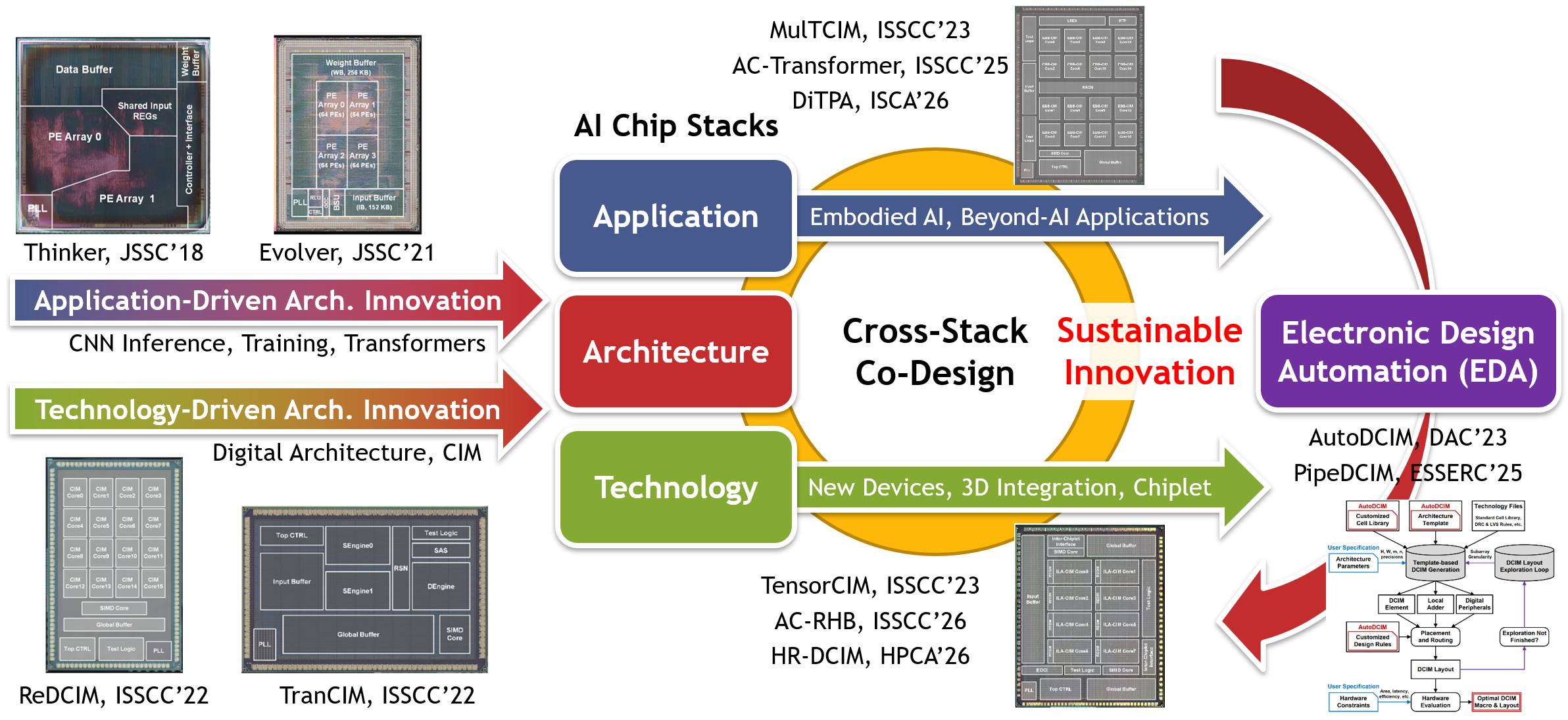
My research focuses on AI Chip with the cross-stack co-design philosophy. :
This is the computer architecture research philosophy I learnt from Prof. Yuan Xie. I have adapted it to AI chip research and taught my students. This page shows my representative research. I also have an AI chip-related paper collection at Neural Networks on Silicon, which is helpful for students to learn the history and SOTA of AI chip and system research.
Application-Driven Architecture Innovation
Embodied AI and Robotics
- [ISCA’26] DiTPA: A DiT-based Action Planner Accelerator Exploiting Action-Denoising-Multimodality Redundancy for Embodied Artificial Intelligence
- [JOS’25] Robotic Computing System and Embodied AI Evolution: An Algorithm-Hardware Co-Design Perspective
Transformers
- [ISSCC’22] TranCIM: A 28nm 15.59uJ/Token Full-Digital Bitline-Transpose CIM-based Sparse Transformer Accelerator with Pipeline/Parallel Reconfigurable Modes (Extended to JSSC’23)
- [ISSCC’23] MulTCIM: A 28nm 2.24uJ/Token Attention-Token-Bit Hybrid Sparse Digital CIM-based Accelerator for Multimodal Transformers (Invited to JSSC’24)
- [ISSCC’25] AC-Transformer: A 28nm 0.22uJ/Token Memory-Compute-Intensity-Aware CNN-Transformer Accelerator with Hybrid-Attention-Based Layer-Fusion and Cascaded Pruning for Semantic-Segmentation (The First Hong Kong AI Chip at ISSCC)
- [JOS’24] Towards Efficient Generative AI and Beyond-AI Computing: New Trends on ISSCC 2024 Machine Learning Accelerators (Invited Paper)
CNN Inference and Training
- [TVLSI’17] DNA: Deep Convolutional Neural Network Architecture with Reconfigurable Computation Patterns (TVLSI No.5/2/6/8/8/9 Downloaded Manuscripts in 2017~2022, 6 Times Monthly No.1 Popular Article)
- [JSSC’18] Thinker: A High Energy Efficient Reconfigurable Hybrid Neural Network Processor for Deep Learning Applications (Thinker was exhibited at the 2016 National Mass Innovation and Entrepreneurship Week, as a representative work from Tsinghua University. The Thinker chip was highly praised by Chinese Premier Li Keqiang, and featured by Yang Lan One on One, AI Tech Talk and MIT Technology Review. It won the ISLPED’17 Design Contest Award, which was the first time that a China Mainland team won this contest.)
- [ISCA’18] RANA: Towards Efficient Neural Acceleration with Refresh-Optimized Embedded DRAM (Covered by Tsinghua University News and AI Tech Talk)
- [JSSC’21] Evolver: A Deep Learning Processor with On-Device Quantization-Voltage-Frequency Tuning (Nomination Award for 2021 Top-10 Research Advances in China Semiconductors).
Technology-Driven Architecture Innovation
SRAM-based Digital CIM
- [ISSCC’22] ReDCIM: A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 Reconfigurable Digital CIM Processor with Unified FP/INT Pipeline and Bitwise in-Memory Booth Multiplication for Cloud Deep Learning Acceleration (Invited to JSSC’23, 2023 Top-10 Research Advances in China Semiconductors, Featured by Synced and HKUST SENG News)
- [ISSCC’22] TranCIM: A 28nm 15.59uJ/Token Full-Digital Bitline-Transpose CIM-based Sparse Transformer Accelerator with Pipeline/Parallel Reconfigurable Modes (Extended to JSSC’23)
- [ISSCC’23] MulTCIM: A 28nm 2.24uJ/Token Attention-Token-Bit Hybrid Sparse Digital CIM-based Accelerator for Multimodal Transformers (Invited to JSSC’24)
- [ISSCC’23] TensorCIM: A 28nm 3.7nJ/Gather and 8.3TFLOPS/W FP32 Digital-CIM Tensor Processor for MCM-CIM-based Beyond-NN Acceleration (Extended to JSSC’24)
Error-Resilient CIM for Large AI Chips
- [HPCA’25] ER-DCIM: Error-Resilient Digital CIM with Run-Time MAC-Cell Error Correction
- [HPCA’26] HR-DCIM: High-Reliability Floating-Point Digital CIM Architecture with Unified Low-Cost Iterative Error Correction
- [JSSC’26] ETCIM: Error-Tolerant Digital CIM Processor with Redundancy-Free Hard Error Repair and Run-Time Soft Error Correction
3D-Stacked AI Chip
- [ISCA’24] Exploiting Similarity Opportunities of Emerging Vision AI Models on Hybrid Bonding Architecture
- [ISSCC’26] AC-Transformer-RHB: A 14.08-to-135.69Token/s ReRAM-on-Logic Stacked Outlier-Free Large-Language-Model Accelerator with Block-Clustered Weight-Compression and Adaptive Parallel-Speculative-Decoding